Deleted File Recovery using foremost

In this post, we'll use the Linux program foremost to recover files, both existing and deleted, from a .dd image. foremost is what is as known as a data-carving utility. It operates by examining data, bit by bit, and extracting sets of data that meet a defined pattern.
As a quick aside, this post is an excerpt from an independent study semester from my time in undergrad. It is rather dated by this point, but hopefully might still be useful to some.
foremost references its configuration file for a set of file headers, footers and other information that it uses to determine whether a set of data actually is a file or not. Since foremost just looks at the file data, and not at any table entries, inodes, or anything similar, it can be used on virtually any image, whether it be of a hard drive, swap file, hibernation file, or RAM dump. It also makes no distinction between existing and deleted files, as long as the deleted files’ headers have not been overwritten. By default foremost can search for the following file types: jpg, gif, png, bmp, avi, exe, mpg, wav, riff, wmv, mov, pdf, ole, doc, zip, rar, htm, and cpp. Other file types can be searched for by adding a custom definition to the configuration file.
foremost finds files by examining the image file for file headers. Most types of files begin and end with a set string of bytes that indicates what type of file it is, and optionally also contain metadata about the file. For example, .jpg files can contain information in them regarding what type of camera created the image. foremost only looks at the header and footer; again, in the case of a .jpg, the header and footer are 0xffd8 and 0xffd9, respectively. When it finds a header that appears in its list, it searches for a set number of bytes for the footer; if it does not find the footer after this number of bytes, it stops searching and moves on to the next header. If it finds a matching footer, it carves out all the data between the header and footer and saves it as a file of the corresponding type. As a result, foremost can only find contiguous files; therefore, if the image is heavily fragmented, it will not find many files.
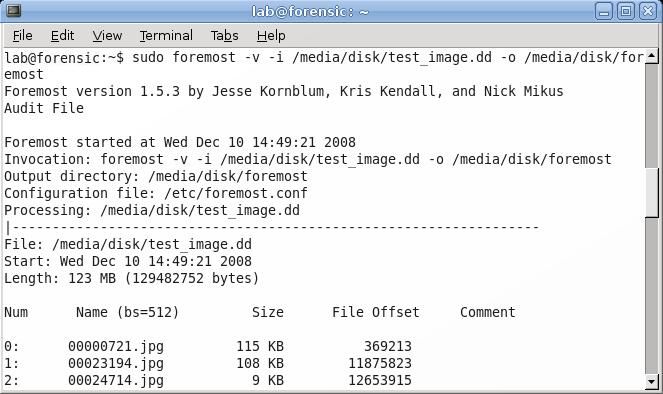
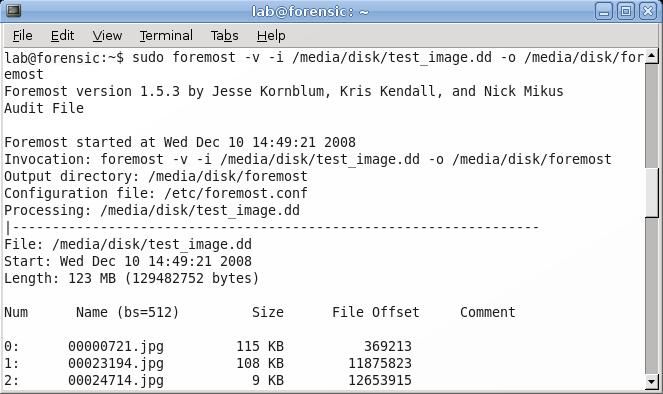
The command that will invoke foremost is given below:
foremost –v –i /media/disk/test_image.dd –o /media/disk/foremost
The –v flag puts foremost in verbose mode, which means it displays information about its progress to the screen. All that information can be found in an audit file that foremost creates, so –v can be omitted if the user desires. The next two flags, -i and –o are the input image file and the output directory, respectively. As entered above, this command will have foremost extract all file types that it recognizes; if the user wants to limit the search to a single file type, for example .jpg, adding the –t jpg flag would extract only files of type .jpg. If the user has created a custom configuration file with additional file signature definitions, foremost can be directed to use that file with the –c flag followed by the path to the configuration file. Like nearly all Linux programs, more information about foremost’s syntax and usage can be found by typing man foremost.
Once foremost starts to run, and the –v flag has been added, it will display on the screen each file that it recovers, showing the name it has given it (since this type of analysis has no way of determining the original filename), the size, the file offset, and a comments section, which can display information such as image dimensions.
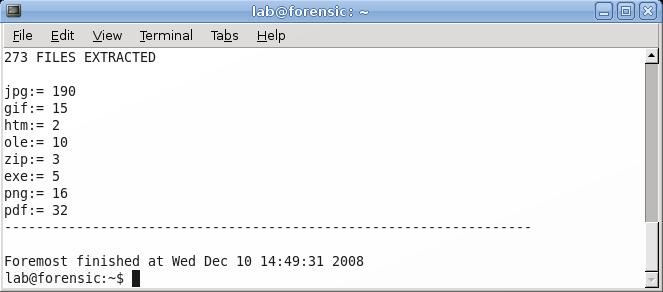
Once foremost has finished running, it will display a summary of what it has found. In this example, foremost was able to carve out 273 files of eight different types.
If the user then navigates to the directory where foremost saved its output, the audit file can be found. This directory has the audit file containing all the information about foremost’s progress and a set of folders, one for each type of extracted file. If the user navigates to the directory where the recovered jpgs reside using a graphical file browser, thumbnails of all the recovered images can be seen. In many situations, this is the best way to view the images, as the generated names of the images will be meaningless. However, if the user is looking for a specific image and knows its file size, it is possible to search through the files that way instead of visually inspecting them.
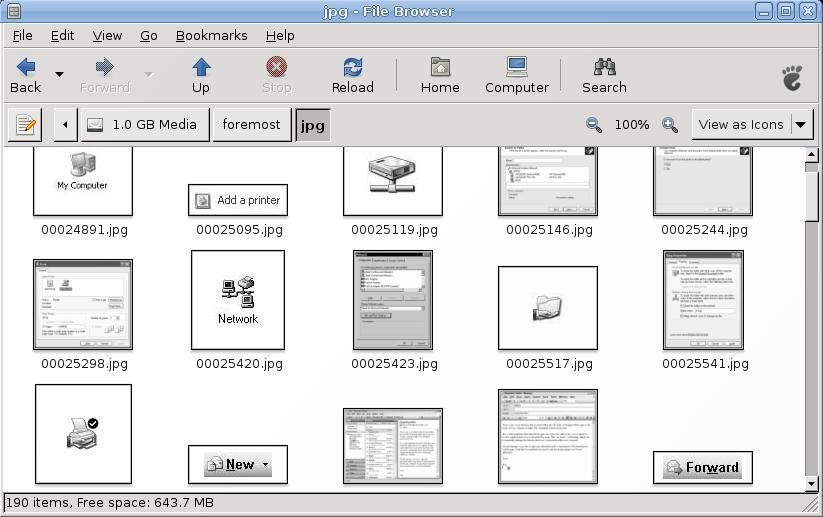
If the user is searching for a specific text document, she should look in the ole directory. OLE was developed by Microsoft and stands for Object Linking and Embedding. OLE allows embedding of documents within one another; an example of this is when a user places a picture inside a Microsoft Word document. foremost will detect many Word documents as type ole instead of doc or docx. Therefore, if a user is interested in text files, she should examine both the ole and doc directories, if they exist.
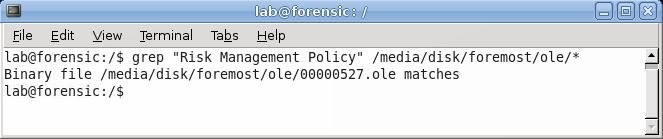
If the investigator is searching for a single document, one fast way of searching is to use the command grep. In this example, supposed the investigator is looking for a "Risk Management Policy". To quickly search all the files instead of examining them all individually, she could use the command:
grep “Risk Management Policy” /media/disk/foremost/ole/*
This instructs grep to look inside all the files in the /media/disk/foremost/ole/ directory for the string “Risk Management Policy”. In this case, the search was successful, and one file was found that contained that string. By default, when multiple files are searched grep displays the name of the file in which the match was found.