Authenticating Screenshots from Netflix's Carry-On Movie
I watch Netflix's Carry-On, notice a real Google Search URL on screen, extract lots of data points from it and "authenticate" the screenshot.

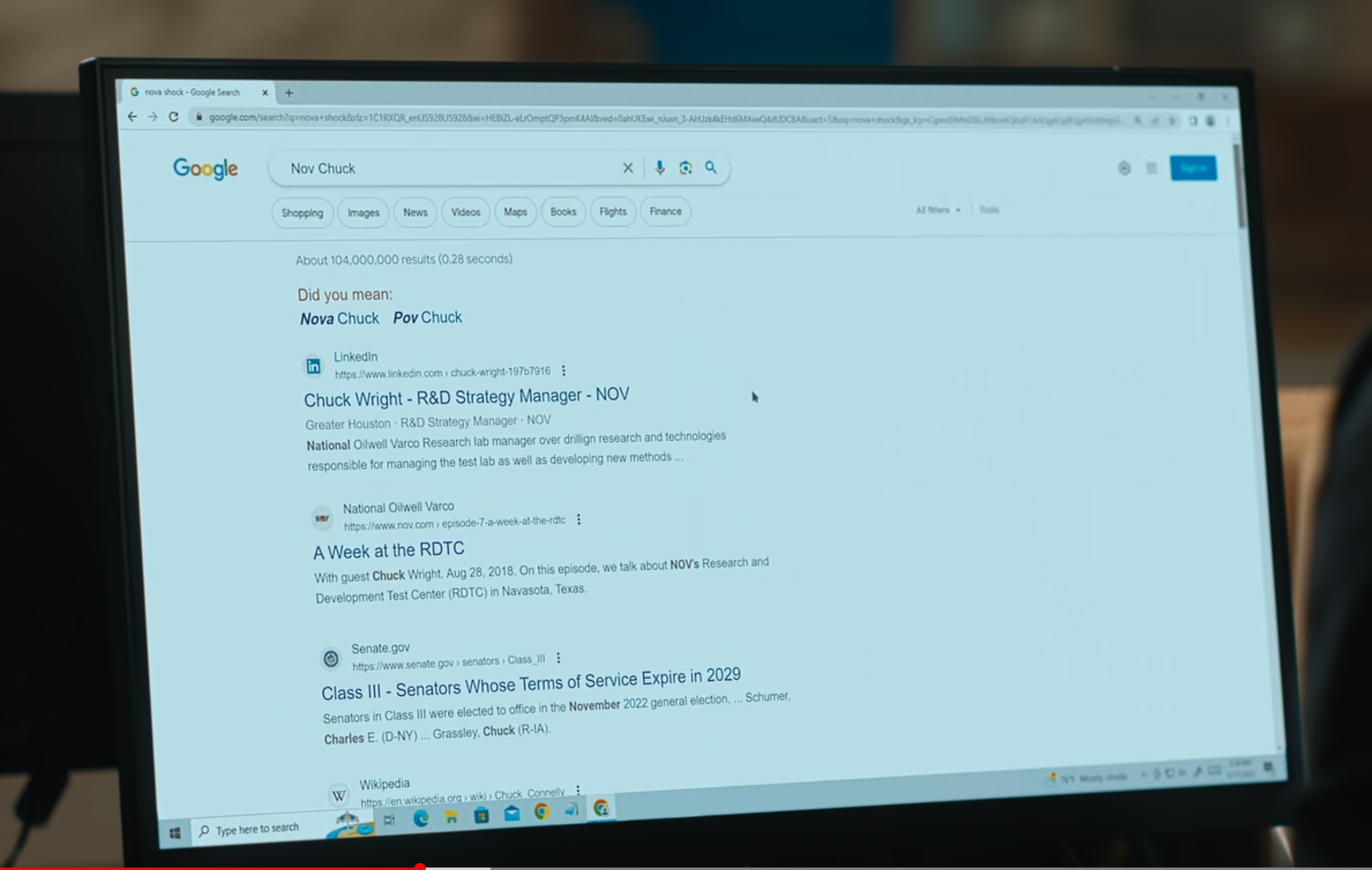
Over the winter holiday, I got a bit of downtime. During this, I was watching Netflix's Carry-On when I noticed something: an actual URL on screen! Often in movies and TV, any "web browsers" that appear are mock-ups (and either look awesomely futuristic or laughable bad). Not only did this appear to be a real-life web browser showing a real webpage, it was a Google Search Engine Results Page (SERP), which I know can have tons of interesting bits encoded in it. My wife chuckled at me as I paused the movie to take a closer look (she's used to that by now). Here it is:
The next day, I went back to that scene (about 47 minutes in, if you want to see it yourself) and did my best to type out the URL. I got as far as the oq query string parameter then gave up, as the image was getting blurry and I already had quite a bit. For the Google SERP URL, I was able to read the q, rlz, ei, ved, uact, and oq query string parameters. I put the URL into Unfurl, and got:
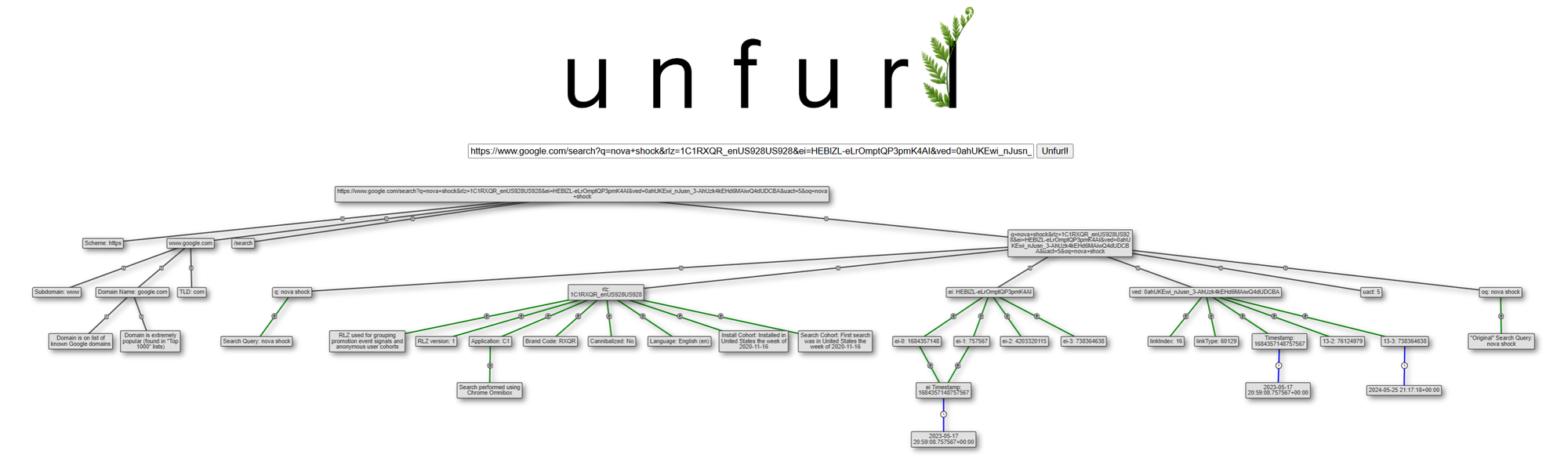
There's a ton of stuff here! If you don't know what all those Google Search parameters mean, no problem; Unfurl does its best to parse and explain them. I'd encourage you to take a look at the interactive graph yourself; there's useful hover text on some nodes that isn't visible in the screenshot above.
I'll summarize what Unfurl pulled out of each query string parameter from the Carry-On Google SERP URL:
q: "nova shock" - the terms used in the Google search queryoq: "nova shock" - the "original query" terms entered by the user.- Sometimes auto-complete or suggestions are used to reach the actual search terms (in
q) from theoqvalue, but that doesn't look to have happened here, since theqandoqare the same.
- Sometimes auto-complete or suggestions are used to reach the actual search terms (in
rlz: this is used for grouping promotion event signals and anonymous user cohorts (more info onrlzin this post). Interesting parsed info:- the search was performed using Chrome Omnibox (that combination URL and search box at the top of Chrome)
- the language was English
- the Chrome browser used to make the search was installed in United States the week of 2020-11-16, which is also the same time period the first Google search was made from that system
ei: has info about when the search session started. The search session starting timestamp is before the actual search occurred; this is often seconds before, but could be many hours.- The search session started 2023-05-17 20:59:08.757567+00:00
ved: often appears when a user clicks a link on a Google page. It contains information about the link that was clicked on: position on the page, link type, and timing (more info onvedin this post).- The search session started 2023-05-17 20:59:08.757567+00:00 (matches the
eitimestamp)
- The search session started 2023-05-17 20:59:08.757567+00:00 (matches the
That's a lot of information extracted from one URL! Most of the time when I'm doing this kind of analysis, I don't have a video (or screenshot) of the user doing the actions in the browser, and the data points from the URL can help paint the full picture of what happened. In this instance, however, we can see what the user was doing, which lets us ask a different question: is what is encoded in the URL consistent with what we're seeing? Or phrased another way: has the screenshot been manipulated?
Is the Carry-On screenshot consistent with the movie setting?
So, how did the Carry-On screenshot do as far as being consistent with the events around it? Let's go through each data point from the URL and see how it fits with what we see in the movie:
| Attribute | On-Screen | Extracted Data Point | Match |
|---|---|---|---|
| Search query | "Nov Chuck" | "nova shock" | ❌ |
| Browser is Chrome | Yes | Yes | ✅ |
| Search location | Google Home Page or New Tab Page |
Omnibox | ❌ |
| Language | English | English | ✅ |
| Browser installed 2020-11-16 | Unknown | Unknown | ❔ |
| Search session start | 2023-05-17 | 202?-12-24 | ❌ |
Conclusion: The screenshot has been altered! 😲
I know, who could have guessed a computer screen in a movie had some edits applied? The search query from the URL didn't match what was on the screen, which is the most definitive mismatch I can see. The two matching attributes, the browser being Chrome and the language being English, are so common that it would be strange if they didn't match. The search location mismatch (Omnibox vs Home Page) I don't weigh heavily, as I've had a hard time getting a rlz parameter to appear in SERP URLs, so I haven't been able to verify its behavior. Likewise, the browser install date from the rlz is plausible, but not useful for verification in this case.
The last big mismatch is on the search session timestamp. While the search session starting timestamp can be a ways before the search actually occurs, 7 month is quite a stretch (as the movie is set on December 24th and the embedded timestamp is May 17th). However, if you kind of squint at the computer's clock while the search is happening, it might resemble 5/1?/????. So maybe the computer and the Google search agree on the date at least, but the people on-screen aren't being honest about what the timeframe is? 🧐

Real Life Applications
Evaluating the Authenticity of Screenshots
Now, this post is just a fun exercise (no one expects screenshots from movies to match reality), but it does have more serious parallels. If you come across a screenshot, whether that's during a DFIR investigation, some OSINT research, or just on social media, if that screenshot has a URL in it, you potentially have some more data points around the veracity of that screenshot.
This post highlighted how useful something like a search engine URL can be, but all sorts of URLs can have interesting bits encoded inside them, like those from Twitter/X, Discord, TikTok, and many more!
Importance of Verification
Above, when I said I just typed out the URL from Carry-On and dropped it into Unfurl to get all those results, I wasn't being completely honest. I did put my transcribed URL into Unfurl, but when I took a close look at the results I noticed things weren't quite right.
Some of the things we've observed about the URLs are useful, like what we think the timestamps represent, and some are more like trivia. One of the less-useful things we've figured out is that the last (or 3rd) value in the ei parameter should match the 13-3 value in the ved parameter. We don't know what the meaning of these values, but after looking at enough examples, we expect them to match. And in my first transcribed example... they don't. We also expect the timestamps in the ved and the ei to match, and those don't either. What's going on?
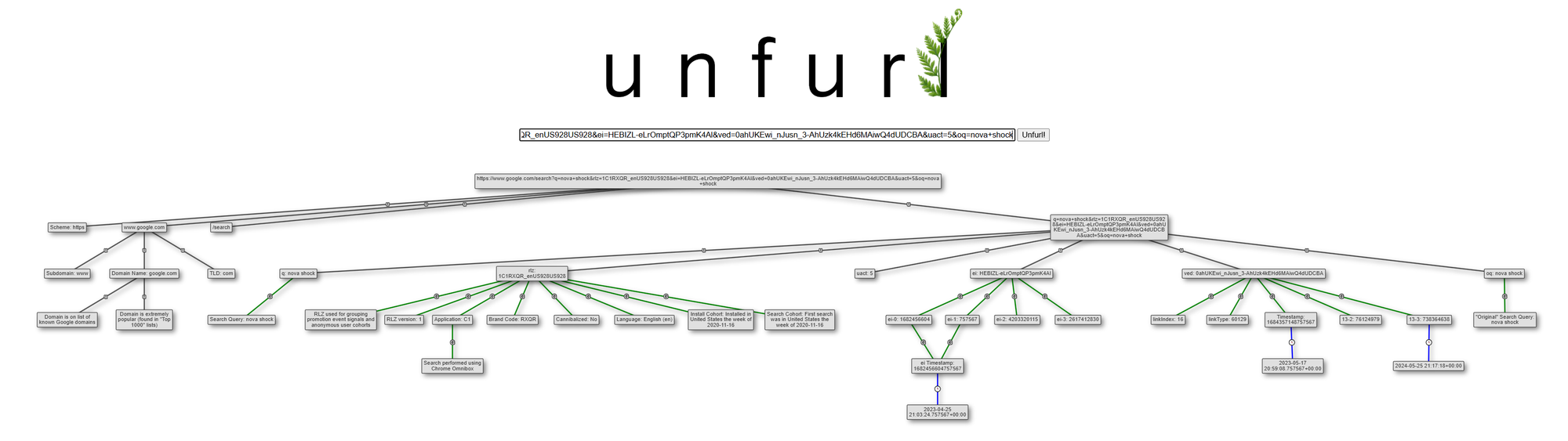
This led me to experiment with the ei and ved parameters; specifically, with the characters that can be a little ambiguous (like lowercase "L" (l) and uppercase "i" (I). After some tinkering, I found that I had initially misread two characters, both in the ei parameter. The correct value was HEBlZL-eLrOmptQP3pmK4AI; previously I had the 4th and last characters switched with their homoglyphs (HEBIZL-eLrOmptQP3pmK4Al). This helps illustrate that even "trivia"-type knowledge has its uses; while I don't know what those values mean, I was able to use them as a kind of consistency check.
Try It Out!
That's it for this post. If you found it interesting, I'd encourage you to try it on a screenshot you find and let me know how it goes! Unfurl is useful for this, and you can use it online or locally.